Getting Started
Authors: Robert Gordon-Smith, Brian Schilder, Nathan Skene
Authors: Robert Gordon-Smith, Brian Schilder, Nathan Skene
Vignette updated: Nov-14-2023
Source: Vignette updated: Nov-14-2023
vignettes/MultiEWCE.Rmd
MultiEWCE.Rmd## Registered S3 method overwritten by 'ggtree':
## method from
## fortify.igraph ggnetworkIntroduction
The MultiEWCE package is an extension of the EWCE
package. It is designed to run expression weighted celltype enrichment
(EWCE) on multiple gene lists in parallel. The results are
then stored both as separate .rds files, one for each
individual EWCE analysis, as well as a in a single
dataframe containing all the results.
This package is useful in cases where you have a large number of related, but separate, gene lists. In this vignette we will use an example from the Human Phenotype Ontology (HPO). The HPO contains over 9000 clinically relevant phenotypes annotated with lists of genes that have been found to be associated with the particular phenotype.
Loading Phenotype Associated Gene Lists from the HPO
The MultiEWCE package requires the gene data to be in a particular format. It must be a data.frame that includes one column of gene list names, and another column of genes. For example:
| hpo_name | Gene |
|---|---|
| “Abnormal heart” | gene X |
| “Abnormal heart” | gene Y |
| “Poor vision” | gene Z |
| “Poor vision” | gene Y |
| “Poor vision” | gene W |
| “Short stature” | gene V |
etc…
Now we will get a dataset like this from the HPO.
gene_data <- HPOExplorer::load_phenotype_to_genes()## Reading cached RDS file: phenotype_to_genes.txt## + Version: v2023-10-09| hpo_id | hpo_name | ncbi_gene_id | gene_symbol | disease_id |
|---|---|---|---|---|
| HP:0025115 | Civatte bodies | 64131 | XYLT1 | OMIM:264800 |
| HP:0025115 | Civatte bodies | 64132 | XYLT2 | OMIM:264800 |
| HP:0025115 | Civatte bodies | 368 | ABCC6 | OMIM:264800 |
| HP:0025114 | Hypergranulosis | 242 | ALOX12B | OMIM:242100 |
| HP:0025114 | Hypergranulosis | 59344 | ALOXE3 | OMIM:242100 |
| HP:0025114 | Hypergranulosis | 4014 | LORICRIN | OMIM:604117 |
In this example our gene list names column is called
Phenotype and our column of genes is called
Gene. However, different column names can be specified to
the MultiEWCE package.
Setting up input arguments for the gen_results function
# Loading CTD file
ctd <- load_example_ctd()
list_names <- unique(gene_data$hpo_id)[seq(10)]
reps <- 10 # in practice would use more reps
cores <- 1 # in practice would use more cores
save_dir <- file.path(tempdir())
save_dir_tmp <- file.path(save_dir,"results")ctd
The ctd (cell type data) file contains the single cell
RNA sequence data that is required for EWCE. for further information
about generating a ctd please see the EWCE
documentation. In this example we will use a CTD of human gene
expression data, generated from the Descartes Human Cell Atlas. Replace
this with your own CTD file.
gene_data
Gene data is the dataframe containing gene list names and genes, in
this case we have already loaded it and assigned it to the variable
gene_data.
list_names
This is a character vector containing all the gene list names. This
can be obtained from your gene_data as follows. To save
time in this example analysis we will only use the first 10 gene lists
([1:10])
bg
This is a character vector of genes to be used as the background
genes. See EWCE package docs for more details on background
genes.
Column names
list_name_column is the name of the column in gene_data
that contains the gene list names and gene_column contains
the genes.
Processing results arguments
The save_dir argument is the path to the directory where
the individual EWCE results will be saved.
The force_new argument can be set to TRUE
or FALSE and states if you want to redo and overwrite
analysis of gene lists that have already been saved to the
save_dir. Setting this to FALSE is useful in
cases where you stopped an analysis midway and would like to carry on
from where you left off.
Number of cores
The cores argument is the number of cores you would like
to run in parallel. This is dependent on what is available to you on
your computer. In this case we will just run it on one core, no
parallelism.
EWCE::bootstrap_enrichment_test arguments
The gen_results function calls the
EWCE::bootstrap_enrichment_test function. Here we set the
input parameters related to this.
reps is the number of bootstrap reps to run, for this
tutorial we will only do 10 to save time, but typically you would want
to do closer to 100,000.
Run analysis
Now we have set up all our desired inputs, we can run the analysis.
all_results <- MultiEWCE::gen_results(ctd = ctd,
gene_data = gene_data,
list_names = list_names,
list_name_column = "hpo_id",
reps = reps,
cores = cores,
save_dir = save_dir,
force_new = TRUE,
save_dir_tmp = save_dir_tmp) ## Validating gene lists..## 3 / 10 gene lists are valid.## Retrieving all genes using: gprofiler## Retrieving all organisms available in gprofiler.## Using stored `gprofiler_orgs`.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: hsapiens## Gene table with 62,663 rows retrieved.## Returning all 62,663 genes from human.## Returning 62,663 unique genes from entire human genome.## + Version: 2023-11-14## Background contains 62,663 genes.## Computing gene counts.
## Computing gene counts.
## Computing gene counts.## Done in: 68.5 seconds.##
## Saving results ==> /tmp/RtmpXS0WUt/gen_results.rdsVisualise the results
Just as an example, we will create a plot showing the number of significant enrichments per phenotype in the all_results data.frame. We will use q <= 0.05 as the significance threshold.
library(ggplot2)
library(data.table)
#### Aggregate results ####
n_signif <- all_results[q<=0.05 & !is.na(q),
list(sig_enrichments = .N,
mean_fold_change=mean(fold_change)),
by="hpo_id"]
#### Plot ####
plot1 <- ggplot(n_signif, aes(x = stringr::str_wrap(hpo_id,width = 10),
y = sig_enrichments,
fill = mean_fold_change)) +
geom_col() +
labs(x="Phenotype",y="Enrichments (n)") +
theme_bw()
methods::show(plot1)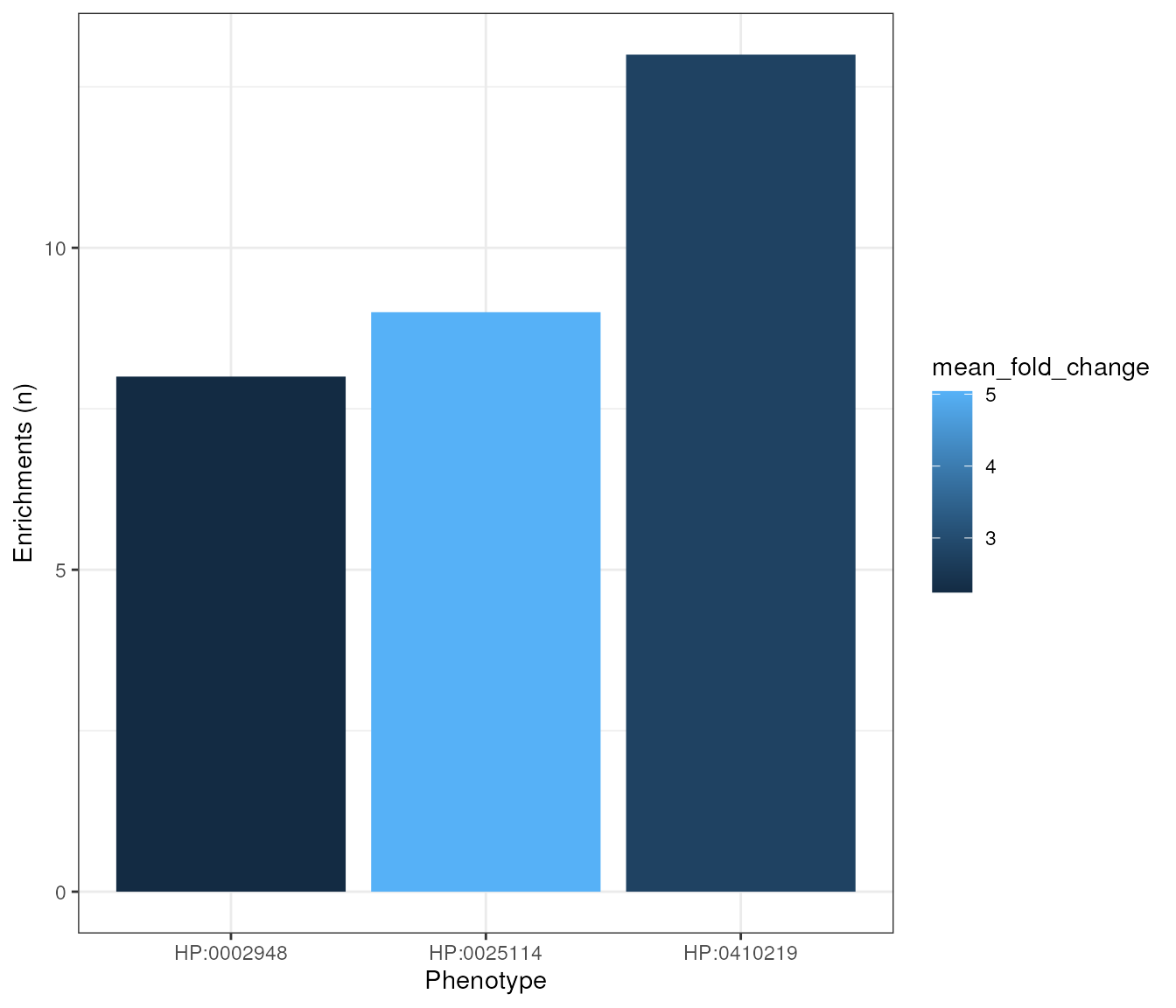
Other functions in MultiEWCE
merge_results
If you have a results directory of individual EWCE results but do not
have the merged dataframe of all results, you can call the
merge_results function manually. The save_dir
argument is the path to your results directory and the
list_name_column argument is the name of the column
containing gene list names. In this case we used “Phenotype” as this
column name when we generated the results.
all_results_2 <- MultiEWCE::merge_results(save_dir = save_dir_tmp)get_gene_list
This function gets a character vector of genes associated with a particular gene list name.
phenotypes <- c("Scoliosis")
gene_set <- HPOExplorer::get_gene_lists(phenotypes = phenotypes,
phenotype_to_genes = gene_data)## Translating all phenotypes to HPO IDs.## ℹ All local files already up-to-date!## + Returning a vector of phenotypes (same order as input).
cat(paste(length(unique(gene_set$gene_symbol)),
"genes associated with",shQuote(phenotypes),":",
paste(unique(gene_set$gene_symbol)[seq(5)],collapse = ", ")))## 1084 genes associated with 'Scoliosis' : PIK3CA, FBXL4, TBX5, TRAPPC4, LZTR1get_unfinished_list_names
This function is used to find which gene lists you have not yet analysed
all_phenotypes <- unique(gene_data$hpo_id)
unfinished <- MultiEWCE::get_unfinished_list_names(list_names = all_phenotypes,
save_dir_tmp = save_dir_tmp)
methods::show(paste(length(unfinished),"/",length(all_phenotypes),
"gene lists not yet analysed"))## [1] "10966 / 10969 gene lists not yet analysed"Run disease-level enrichment tests
So far, we’ve iterated over gene list grouped by phenotypes. But we can also do this at the level of diseases (which are composed of combinations of phenotypes).
gene_data <- HPOExplorer::load_phenotype_to_genes("genes_to_phenotype.txt")## Reading cached RDS file: genes_to_phenotype.txt## + Version: v2023-10-09
#### Filter only to those with >=4 genes ####
gene_counts <- gene_data[,list(genes=length(unique(gene_symbol))),
by="disease_id"][genes>=4]
list_names <- unique(gene_counts$disease_id)[seq(5)]
all_results <- MultiEWCE::gen_results(ctd = ctd,
gene_data = gene_data,
list_name_column = "disease_id",
list_names = list_names,
annotLevel = 1,
force_new = TRUE,
reps = 10)## Validating gene lists..## 5 / 5 gene lists are valid.## Retrieving all genes using: gprofiler## Retrieving all organisms available in gprofiler.## Using stored `gprofiler_orgs`.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: hsapiens## Gene table with 62,663 rows retrieved.## Returning all 62,663 genes from human.## Returning 62,663 unique genes from entire human genome.## + Version: 2023-11-14## Background contains 62,663 genes.## Computing gene counts.
## Computing gene counts.
## Computing gene counts.
## Computing gene counts.
## Computing gene counts.## Done in: 104.9 seconds.##
## Saving results ==> /tmp/RtmpXS0WUt/gen_results.rdsFull analysis
Run the following code the replicate the main analysis in the study described here.
gene_data <- HPOExplorer::load_phenotype_to_genes()
gene_data[,n_gene:=length(unique(gene_symbol)),by="hpo_id"]
gene_data <- gene_data[n_gene>=4,]
ctd <- load_example_ctd("ctd_DescartesHuman.rds")
all_results <- MultiEWCE::gen_results(ctd = ctd,
list_name_column = "hpo_id",
gene_data = gene_data,
annotLevel = 2,
reps = 100000,
cores = 10)Session info
utils::sessionInfo()## R Under development (unstable) (2023-11-08 r85496)
## Platform: x86_64-pc-linux-gnu
## Running under: Ubuntu 22.04.3 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
## LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.20.so; LAPACK version 3.10.0
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
##
## time zone: UTC
## tzcode source: system (glibc)
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] data.table_1.14.8 ggplot2_3.4.4 MultiEWCE_0.1.9 BiocStyle_2.31.0
##
## loaded via a namespace (and not attached):
## [1] later_1.3.1 bitops_1.0-7
## [3] ggplotify_0.1.2 GeneOverlap_1.39.0
## [5] filelock_1.0.2 tibble_3.2.1
## [7] ontologyPlot_1.6 ggnetwork_0.5.12
## [9] graph_1.81.0 httr2_1.0.0
## [11] lifecycle_1.0.4 rstatix_0.7.2
## [13] HPOExplorer_0.99.12 rprojroot_2.0.4
## [15] lattice_0.22-5 backports_1.4.1
## [17] magrittr_2.0.3 limma_3.59.1
## [19] plotly_4.10.3 sass_0.4.7
## [21] rmarkdown_2.25 jquerylib_0.1.4
## [23] yaml_2.3.7 httpuv_1.6.12
## [25] HGNChelper_0.8.1 DBI_1.1.3
## [27] RColorBrewer_1.1-3 lubridate_1.9.3
## [29] abind_1.4-5 zlibbioc_1.49.0
## [31] GenomicRanges_1.55.1 purrr_1.0.2
## [33] BiocGenerics_0.49.1 RCurl_1.98-1.13
## [35] yulab.utils_0.1.0 rappdirs_0.3.3
## [37] GenomeInfoDbData_1.2.11 IRanges_2.37.0
## [39] S4Vectors_0.41.1 gitcreds_0.1.2
## [41] tidytree_0.4.5 piggyback_0.1.5
## [43] pkgdown_2.0.7 codetools_0.2-19
## [45] DelayedArray_0.29.0 tidyselect_1.2.0
## [47] aplot_0.2.2 farver_2.1.1
## [49] matrixStats_1.1.0 stats4_4.4.0
## [51] BiocFileCache_2.11.1 jsonlite_1.8.7
## [53] ellipsis_0.3.2 systemfonts_1.0.5
## [55] paintmap_1.0 tools_4.4.0
## [57] treeio_1.27.0 ragg_1.2.6
## [59] Rcpp_1.0.11 glue_1.6.2
## [61] SparseArray_1.3.1 xfun_0.41
## [63] MatrixGenerics_1.15.0 GenomeInfoDb_1.39.1
## [65] RNOmni_1.0.1.2 dplyr_1.1.3
## [67] withr_2.5.2 BiocManager_1.30.22
## [69] fastmap_1.1.1 fansi_1.0.5
## [71] caTools_1.18.2 digest_0.6.33
## [73] timechange_0.2.0 R6_2.5.1
## [75] mime_0.12 gridGraphics_0.5-1
## [77] textshaping_0.3.7 colorspace_2.1-0
## [79] gtools_3.9.4 RSQLite_2.3.3
## [81] utf8_1.2.4 tidyr_1.3.0
## [83] generics_0.1.3 httr_1.4.7
## [85] htmlwidgets_1.6.2 S4Arrays_1.3.0
## [87] ontologyIndex_2.11 pkgconfig_2.0.3
## [89] gtable_0.3.4 blob_1.2.4
## [91] SingleCellExperiment_1.25.0 XVector_0.43.0
## [93] htmltools_0.5.7 carData_3.0-5
## [95] bookdown_0.36 scales_1.2.1
## [97] Biobase_2.63.0 png_0.1-8
## [99] ggfun_0.1.3 knitr_1.45
## [101] reshape2_1.4.4 coda_0.19-4
## [103] statnet.common_4.9.0 nlme_3.1-163
## [105] curl_5.1.0 cachem_1.0.8
## [107] stringr_1.5.0 BiocVersion_3.19.1
## [109] KernSmooth_2.23-22 parallel_4.4.0
## [111] AnnotationDbi_1.65.2 desc_1.4.2
## [113] pillar_1.9.0 grid_4.4.0
## [115] vctrs_0.6.4 gplots_3.1.3
## [117] promises_1.2.1 ggpubr_0.6.0
## [119] car_3.1-2 dbplyr_2.4.0
## [121] xtable_1.8-4 Rgraphviz_2.47.0
## [123] evaluate_0.23 orthogene_1.9.0
## [125] cli_3.6.1 compiler_4.4.0
## [127] rlang_1.1.2 crayon_1.5.2
## [129] grr_0.9.5 ggsignif_0.6.4
## [131] labeling_0.4.3 gprofiler2_0.2.2
## [133] EWCE_1.11.2 plyr_1.8.9
## [135] fs_1.6.3 stringi_1.8.1
## [137] BiocParallel_1.37.0 viridisLite_0.4.2
## [139] ewceData_1.11.0 network_1.18.1
## [141] babelgene_22.9 munsell_0.5.0
## [143] Biostrings_2.71.1 gh_1.4.0
## [145] lazyeval_0.2.2 homologene_1.4.68.19.3.27
## [147] Matrix_1.6-2 ExperimentHub_2.11.0
## [149] patchwork_1.1.3 bit64_4.0.5
## [151] KEGGREST_1.43.0 statmod_1.5.0
## [153] shiny_1.7.5.1 highr_0.10
## [155] SummarizedExperiment_1.33.0 interactiveDisplayBase_1.41.0
## [157] AnnotationHub_3.11.0 broom_1.0.5
## [159] memoise_2.0.1 bslib_0.5.1
## [161] ggtree_3.11.0 bit_4.0.5
## [163] ape_5.7-1